Large vision–language models (LVLMs) have transformed how AI understands the world, but they possess a significant ‘blind spot’: abstract visual inputs like hand-drawn sketches. While text is the primary way we interact with these models, it often fails to describe complex shapes or precise spatial arrangements that a simple sketch can convey instantly. Current state-of-the-art models struggle with sketches because they are highly variable, abstract, and fundamentally different from the photorealistic images these models are typically trained on.
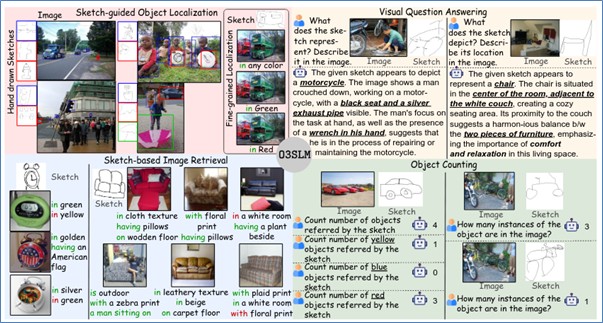
A research team from the Visual Computing Lab (Department of Computational and Data Sciences) at the Indian Institute of Science, comprising Rishi Gupta, Mukilan Karuppasamy, Shyam Marjit, Dr Aditay Tripathi, and Prof Anirban Chakraborty, has successfully addressed this challenge with O3SLM (Open Weight, Open Data, and Open Vocabulary Sketch-Language Model). Presented at the AAAI Conference on Artificial Intelligence (AAAI 2026), O3SLM is the first unified model designed to reason with sketches, photos, and text simultaneously, achieving a level of alignment where previous models consistently failed.
Recognising the lack of open-source datasets for this task, the team introduced SketchVCL, a massive multi-task dataset. Since manually drawing enough sketches for training would be impossible, the team developed an automated generation pipeline and used it to curate over 30 million sketch instances.
O3SLM introduces several groundbreaking capabilities for sketch-based interaction:
Object localisation: The model can find and draw precise bounding boxes around specific objects in a photo based on a hand-drawn sketch query.
Sketch-based counting: It can accurately count how many instances of a sketched object appear in a complex scene.
Sketch-based image retrieval (SBIR): Users can find specific images in a large gallery simply by providing a sketch.
Visual question answering (VQA): The model can answer nuanced questions about a photo by referring to specific objects through sketches, such as describing an object’s colour, purpose, or its relationship to its surroundings.
The team implemented a two-stage training curriculum to build these skills. First, a sketch alignment stage familiarises the model with crude sketches and their relationship to natural images. Second, instruction tuning aligns the model to follow specific task-based instructions.
In evaluations, O3SLM outperformed existing open-source models and even surpassed closed-source giants like GPT-4o and Gemini 1.5 Pro on sketch understanding tasks — a significant milestone for human–AI interaction.
Phone: 080 2293 3799 Email: office.kiac@iisc.ac.in Location: 406, 4th floor, CDS/SERC building, Indian Institute of Science, Bengaluru 560012.
I joined the BTech programme in Mathematics and Computing at the Indian Institute of Science in 2022. My faculty advisor, Professor Viraj Kumar, has guided my academic journey, and I had the opportunity to work under his mentorship during the summer of 2024.
My academic interests focus on artificial intelligence and data science, and I am passionate about applying these technologies to solve real-world challenges and drive innovation in computing.
Looking ahead, I am eager to apply my skills in practical environments, contributing to impactful artificial intelligence and machine learning solutions across industries.
Close
I joined BTech at IISc in 2024.
My faculty advisor is Dr Shashi Jain.
I am interested particularly in artificial intelligence and data structures. I would like to explore the above fields and potentially make a career there.
Close
I am currently pursuing a BTech, having joined in 2024. With a keen interest in programming, I strive to enhance my skills in this dynamic field. My goal is to secure a rewarding job with a competitive salary in the future.
I am guided by my faculty mentor, Professor Prateek Sharma, who supports my academic and professional aspirations.
Close
I joined the Bachelor of Technology in Mathematics and Computing programme at the Indian Institute of Science in 2023. I am interested in quantitative finance and the dynamics of stock markets, especially in understanding the complex math and computational models that drive them. I am fascinated by how data-driven strategies influence investment choices and manage risk in real time.
Looking ahead, I aim to build a career in investment strategy and risk analysis, where I can apply my skills to drive informed, impactful financial decisions.
Close
I am thrilled to be at IISc, the beating heart of excellence in science and engineering in India, and an ecosystem where great challenges meet enterprising minds. IISc is also a wonderful platform that facilitates personal learning and growth in myriad ways.
While my love for science and the zest for academic excellence brought me to IISc, I have also been an elite athlete and a mountaineer. I also enjoy literature and classical music.
I am excited to be a part of a generation of young researchers on whose shoulders rests the responsibility of innovating at the emerging frontiers of computing, artificial intelligence, and data science. Through my undergraduate years in the BTech Mathematics and Computing programme, I hope to dive deep into these disciplines, as well as boldly traverse their intersections with evolutionary theory, computational biology, and the way the human mind works. I hope to explore novel paths that open up opportunities for creating deep tech solutions that serve the emerging needs of society and our planet.
I am delighted to have been selected for the KIAC Kotak scholarship programme and the mentorship of Professor Pandu Rangan, my faculty guide.
Close
I joined The BTech programme in the academic year 2024-25. I am excited to explore various fields of technology in my time at the Institute and continue my pursuit beyond .
Though I have not narrowed down any field of research yet, I aim to make full use of my time at IISc to explore various areas and find out where I wish to establish my niche.
Close
Surbhi Shaw joined the postdoctoral programme at the Kotak IISc AI-ML Centre in July 2024, working under the mentorship of Professor C Pandu Rangan. Her research focuses on post-quantum cryptography and zero-knowledge proofs, exploring advanced cryptographic protocols that can secure digital systems against quantum computing threats.
She obtained her BSc in Mathematics from Scottish Church College, Kolkata (2016), an MSc in Pure Mathematics from the University of Calcutta (2018), and recently earned her PhD from IIT Kharagpur in 2024. She is passionate about advancing cryptographic techniques and aims to continue her career in academia, aspiring to join an institute as an assistant professor.
Close
Akash Pareek joined as a KIAC postdoctoral researcher, hosted by Professor Arindam Khan, in August 2024. Before this, he did his PhD at IIT Gandhinagar under the mentorship of Professor Manoj Gupta, following a Bachelor's degree from Ramakrishna Mission Vidyamandira, Belur.
His research mainly focusses on online algorithms, data structures, combinatorics, and learning augmented algorithms. His current and future work primarily focusses on designing beyond worst-case algorithms using predictions.
Close
I joined the BTech programme in 2024. My faculty advisor is Professor Viraj Kumar. I am interested in computer science and would like to do research in computer science in the future.
Close
Anmol Gill pursues the MTech (Artificial Intelligence) programme at IISc, in the Robert Bosch Centre for Cyber-Physical Systems (RBCCPS), under the guidance of his faculty adviser Pushpak Jagtap.
He is from Sri Ganganagar, Rajasthan and has completed his Bachelor of Technology in Computer Science and Engineering from Sant Longowal Institute of Engineering and Technology, Punjab in 2024.
Close
Himanshu Jain pursues the MTech (Artificial Intelligence) programme at IISc, in the Department of Computational and Data Sciences (CDS), under the guidance of his faculty adviser K Sekar.
He is from Hansi, Haryana and has completed his Integrated Bachelor and Master of Science degree in Physics from the Indian Institute of Science Education and Research (IISER) Mohali, Punjab in 2024.
Close
G Pavithra pursues the MTech (Artificial Intelligence) programme at IISc, in the Robert Bosch Centre for Cyber-Physical Systems (RBCCPS), under the guidance of her faculty adviser Ravi Prakash.
She is from Coimbatore, Tamil Nadu and has completed her Bachelor of Technology (Honours) in Computer Science and Engineering from the National Institute of Technology Tiruchirappalli, Tamil Nadu in 2023.
Close
Gaurav Kumar pursues the MTech (Artificial Intelligence) programme at IISc, in the Robert Bosch Centre for Cyber-Physical Systems (RBCCPS), under the guidance of his faculty adviser Pushpak Jagtap.
He is from Patna, Bihar and has completed his Bachelor and Master of Science dual degree in Mathematics from the National Institute of Technology Agartala, Tripura in 2021.
Close
Shashwat pursues the MTech (Artificial Intelligence) programme at IISc, in the Department of Electrical Engineering (EE), under the guidance of his faculty adviser Chandra Sekhar Seelamantula.
He is from Lucknow, Uttar Pradesh and has completed his Bachelor of Engineering in Computer Science and Engineering from Sant Longowal Institute of Engineering and Technology, Punjab in 2024.
Close
Vedantam Srikar pursues the MTech (Artificial Intelligence) programme at IISc, in the Department of Computational and Data Sciences (CDS), under the guidance of his faculty adviser Deepak N Subramani.
He is from Hyderabad, Telangana and has completed his Bachelor of Technology in Civil Engineering with Mathematics and Computing as second major from the Indian Institute of Technology Hyderabad, Telangana in 2024.
Close
Pukhrambam Akash Singh pursues the MTech (Artificial Intelligence) programme at IISc, in the Department of Electrical Communication Engineering (ECE), under the guidance of his faculty adviser Prathosh A P.
He is from Naranseina Awang Leikai, Bishnupur, Manipur and has completed his Bachelor of Technology in Electrical Engineering from the National Institute of Technology Manipur, Manipur in 2023.
Close
I completed my BTech in Mechanical Engineering from the National Institute of Technology, Nagpur, in 2022. I joined for my PhD in Cyber-Physical Systems at IISc in August 2022. My PhD research is supervised by Professor Shishir Kolathaya in the Stochastic Robotics Lab (StochLab), which is part of the Robert Bosch Centre for Cyber-Physical Systems.
I received the KIAC PhD scholarship in April 2024.
Research focus: My research is on developing a planning and control framework for contact-rich-legged locomotion. The goal is to enable legged robots to be 'contact friendly' and utilise their entire body to perform various locomotion tasks. This will contribute to more generalised mobility of these robots in real-world environments.
In future, I aim to continue working in legged or bio-robotics research, preferably in academia. My goal is to contribute to advancements in robot locomotion, ideally in a role where I can mentor/teach and also collaborate with other researchers in this field.
Close
I completed my BS-MS in Electrical Engineering and Computer Science from the Indian Institute of Science Education and Research Bhopal, Madhya Pradesh, in 2023. I joined the PhD programme at IISc in August 2023 under the guidance of Professor Punit Rathore in the VISTA Lab at the Robert Bosch Centre for Cyber-Physical Systems.
I was awarded a PhD scholarship from KIAC in April 2024.
Research focus: My current research focusses on multimodal representation learning for healthcare. In future, I plan to delve deeper into causality and interpretability in machine learning for healthcare applications. I also aim to collaborate with hospitals and healthcare professionals to address real-world problems, making significant contributions to the field.
Close
I hold an MS by Research in Data Science from the International Institute of Information Technology Bangalore, Bengaluru and a Bachelor's degree in Electronics and Communication from the LNM Institute of Information Technology, Jaipur. Currently, I am a PhD student at IISc, having commenced my doctoral studies in August 2022. I am conducting my research under the mentorship of Professor Prathosh A P in the Representation Learning Lab, which is affiliated to the Department of Electrical and Communication Engineering.
In April 2024, I was honoured to receive the KIAC PhD scholarship to further support my research pursuits.
Research focus: My research focusses on designing methods for efficient and explainable training of machine learning models in noisy environments, with a primary application in healthcare, particularly in cancer research. As part of my doctoral work, I aim to develop tools that integrate domain expertise to enhance the training of machine learning models.
Close
I am a final year student at the Birla Institute of Technology and Science Pilani, pursuing Mechanical Engineering.
I am extremely grateful for the opportunity to pursue my research internship under the guidance of Professor Debasish Ghose, Senior Professor at the Robert Bosch Centre for Cyber-Physical Systems and Department of Aerospace Engineering, IISc.
I have always been enthusiastic and passionate about the field of robotics and automation. Throughout my undergrad, I have developed a deep fascination for autonomous vehicles and unmanned aerial vehicles (UAVs), especially the complex interactions and systems that enable them to function synchronously.
About my research
My current research at IISc is based on creating automated drone corridors, using AI/ML tools, in a 5G network, ensuring continuous and stable communication between UAVs and 5G base stations throughout the entire flight path. By combining pathfinding algorithms, signal modelling, and machine learning, I aim to ensure stable connectivity and obstacle avoidance.
I am incorporating neural networks to predict 5G signal intensity at points where the required information is not available. The project aims to leverage AI/ML tools to produce multiple conflict-free drone corridors with sufficiently high tracking accuracies and safety margins. This can be achieved by training the AI/ML tool on the 5G network node locations and available terrain data.
By integrating the dynamics of UAV motion with 5G network architecture, I am gaining hands-on experience in an area that combines both my technical skills and research interests.
With the wonderful start and the strong foundation that I have got at IISc, I would like to continue my research in this field and build further upon it, identify the real-world challenges for which my research can be applied, to make the systems more robust and agile.
Close
I am a research intern in the Future Computing Systems (FIST) Lab at the Department of Computer Science and Automation at IISc.
I am currently pursuing my BE in Electronics and Communication Engineering at the Birla Institute of Technology and Science Pilani, Hyderabad campus and I am here for my undergraduate thesis under the supervision of Professor Sumit Kumar Mandal.
I am passionate about digital circuit designs, computer architecture, emerging memory technologies for in-memory computing and neuromorphic computing.
About my research
My work includes contributions to literature on in-memory computing based 2.5D systems for DNN (deep neural network) training acceleration. DNN training on chiplet-based architectures can potentially outperform conventional processors and graphics processing units. My ongoing work focusses on implementing preventive and recovery measures on these accelerators to avoid loss of effort in case of system failure.
Close
I am doing my BE from the Birla Institute of Technology and Science Pilani, Pilani campus. I am working as a KIAC intern from August 2024 and pursuing my Bachelor's thesis here at IISc in the Visual Image Processing Lab at the Department of Electrical Communication Engineering, mentored by Professor Rajiv Soundararajan.
My academic interests include artificial intelligence and machine learning, with a special focus on computer vision and graphics.
About my research
I am working on sparse input novel view synthesis using 3D Gaussian splatting techniques. In the future, I would like to do more research in this domain and make a significant impact both in academia as well as its wide applications in the industry.
Close
I am a BTech graduate in Mechatronics Engineering from the Manipal Institute of Technology, Manipal, currently involved in research at IISc. Under the mentorship of Professor Pushpak Jagtap in the Formal Control and Autonomous Systems (FOCAS) Lab at the Robert Bosch Centre for Cyber-Physical Systems, my academic and professional journey has been enriched by exposure to cutting-edge technologies and methodologies in AI and control systems.
Through my internship at KIAC, I have gained significant hands-on experience in research, paving the way for a deeper understanding of this ever-evolving field.
About my research
My current research revolves around safety-based control and machine learning, specifically focussing on learning from demonstration and open-vocabulary mobile manipulation. These areas explore innovative methods to improve how systems learn tasks from human demonstrations while ensuring safety and expanding language interaction capabilities in mobile robots. This research has applications in enhancing human-robot collaboration, especially in environments that require safe and adaptable control systems, a growing necessity in many fields.
Close
I hold a BTech in Mechatronics from the Manipal Institute of Technology, Manipal where I graduated in 2024. In May 2024, I was awarded an internship from KIAC, which I began in June. I am fortunate to work under the mentorship of Professor Ravi Prakash in the HiRo Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc.
My domains of interest are robotics, dynamics and control systems, and soft robotics.
About my research
My research primarily involves two topics. The first is learning from demonstration using spatio-temporal tubes, a technique that enables robotic systems to learn complex tasks through observation and mimicry. The second area involves open vocabulary mobile manipulation on the Hello Robot Stretch platform, focussing on creating a versatile robotic system capable of adapting to varied and dynamic tasks within unstructured environments. Both projects combine elements of robotics and machine learning, offering exciting opportunities to explore innovative control methods.
Close
I have completed my BTech in Computer Science and Engineering from Sri Sai University, Palampur in 2023 and am currently pursuing my MTech in Artificial Intelligence from the National Institute of Technology, Jalandhar. I received the KIAC internship in June, 2024, and I am working under Professor Radhakant Padhi in the ICGEL (Lab) at the Department of Aerospace Engineering, IISc.
My academic interests include deep learning, machine learning, and natural language processing.
About my research
My research currently focusses on predicting the carbohydrates and calories present in food items using deep learning and computer vision. In future, after completion of my internship and Master's next year, I will go for higher studies and pursue a PhD and will continue my research journey.
Close
I am currently in my seventh semester of a BTech in Computer Science and Engineering at the Indian Institute of Information Technology Kottayam. Since June 2024, I have been a KIAC research intern, working under Professor Punit Rathore in the VISTA Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc. My academic interests centre on impactful AI research, with a particular focus on graph theory, spectral theory, and graph neural networks (GNNs).
About my research
My research so far includes developing parameter-efficient GNNs, exploring the effects of homophily and heterophily on GNNs, analysing GNN expressivity, and investigating graph transformers and spatio-temporal GNNs. My current projects involve modelling large-scale GNNs for billion-node graphs and developing spatio-temporal GNNs for traffic flow analysis.
Looking ahead, I aspire to pursue a PhD in GNNs, especially large-scale and temporal graph networks, as they hold substantial potential in industry and real-world applications. I am also keen to delve into unsupervised and self-supervised GNN approaches, higher-order topologies such as simplicial and cell complexes, and cutting-edge topics like graph-based retrieval-augmented generation (RAG) techniques.
Close
I am a final-year BTech student in Computer Science with a specialisation in Data Science at the Presidency University, Bengaluru. I began my KIAC internship in July 2024 under the guidance of Professor Pandarasamy Arjunan in the Energy Informatics Lab and Sayli Santosh Sawant (MTech student; mentor) at the Robert Bosch Centre for Cyber-Physical Systems, IISc.
I am deeply interested in machine learning, artificial intelligence, and neural networks. These fields are at the core of my studies, and I am passionate about exploring their applications in data-driven problem solving.
About my research
My research focuses on energy distribution analysis. This includes developing user interfaces and data analysis frameworks using tools such as DashApp to visualise and analyse data effectively.
I aspire to work as an ML engineer, Python developer, and data scientist, contributing to innovative solutions in machine learning and data science.
Close
I recently completed my BTech in August 2024 from the Vellore Institute of Technology, Chennai, with a major in Electronics and Communication Engineering. From May 2024, I am a research intern, supported by the Kotak-IISc AI/ML Centre, in the Human-Interactive Robotics (HiRo) Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc. I am working under the guidance of Professor Ravi Prakash. My essential area of interest lies in robot learning, which lies under the general area of AI and robotics.
About my research
Currently, I am working on language-instructed low-level robot action representation and modification with large language models. I am planning to dedicate my next few years in an extended research towards a PhD in the above-mentioned fields.
Close
I received my BTech degree in Electrical Engineering from the Indian Institute of Technology Bhubaneswar, Odisha in the year 2016. I joined the PhD programme in the interdisciplinary department of Brain, Computation, and Data Science in January 2024 under the joint guidance of Professor Venkatesh Babu Radhakrishnan (primary advisor, Department of Computational and Data Sciences) and Professor S P Arun secondary advisor, Centre for Neuroscience).
I received the PhD scholarship from KIAC in April 2024.
Research focus: Although this is my first year of PhD, I intend to research and explore deep vision/multimodal models to understand properties such as robustness, generalisability, compositionality, and training efficiency from a data and model perspective.
Though no one can predict what our future holds and what our endeavours would be, one thing I am sure of is that I would still be pursuing my passion of progressing deeper and gaining a more fundamental understanding of the systems around me, especially related to machine learning. I would try to contribute more towards the twin initiatives of AI for Science and AI for Neuroscience (also known as NeuroAI).
Close
I am very much passionate about computer vision. The applications of computer vision mainly in the fields of generative AI, domain adaptation, and medical imaging have really made me more enthusiastic to contribute more in this domain.
I have done my BTech in Computer Science and Technology (2020-24) from the Indian Institute of Engineering Science and Technology, Shibpur. I received the KIAC predoctoral fellowship in June 2024 and I am working under the guidance of Professor Soma Biswas in the Image Analysis and Computer Vision Lab at the Department of Electrical Engineering, IISc.
My research is on generalisability of deep fake image detection techniques. In future, I would like to pursue higher studies in computer vision.
Close
My interests are in computer vision and self-supervised learning.
I have completed my BE in Computer Science. I received the KIAC predoctoral fellowship in June 2024 and I work with my faculty mentor Professor Punit Rathore in the VISTA Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc.
My current research is on neural architecture search and contrastive learning. My future plan is to pursue a career in research, either by pursuing a PhD or working as a research scientist.
Close
My primary academic interests lie in turbulence and the application of machine learning in engineering. I am particularly passionate about exploring computational methods and AI techniques for simulating complex fluid phenomena, especially in turbulence modelling.
I hold a BTech in Aerospace Engineering (2020-24) from the Indian Institute of Engineering Science and Technology, Shibpur. I started receiving the KIAC predoctoral fellowship from August 2024, which has played a significant role in supporting my research efforts and academic progression. I am currently working under the guidance of Professor Rishita Das in the Turbulence Physics and Computational Research Laboratory (TPCRL) within the Department of Aerospace Engineering at IISc.
My research focuses on developing deep learning and machine learning models to generate synthetic turbulence data that replicates realistic turbulent flow dynamics. Specifically, I am working on models that capture both spatial and temporal dynamics of turbulence, aiming to generate velocity fields across varying Reynolds numbers. In future, I aspire to advance the research in computational fluid dynamics and machine learning with a focus on creating scalable models that can be applied to real-world engineering challenges, particularly in aerospace applications.
Close
My research interests lie in the areas of computer vision (CV) and graph neural networks (GNNs), with a particular focus on developing parameter-efficient and computationally-optimised models that can be applied to real-world datasets.
I am a recent graduate from the Netaji Subhas University of Technology, Delhi, where I completed my Bachelor's degree in Electronics and Communication Engineering with a specialisation in AI and ML. Following my graduation, I was fortunate to receive a predoctoral fellowship from KIAC. Currently, I am serving as a predoctoral researcher in the VISTA Lab, IISc, under the guidance of Professor Punit Rathore from the Robert Bosch Centre for Cyber-Physical Systems. My association with Professor Rathore began during my Bachelor's thesis, where I focussed on optimisation techniques and computer vision problem statements.
I am collaborating with the National Payments Corporation of India (NPCI) to create scalable and efficient GNNs to detect fraudulent transactions. Looking ahead, I am keen to explore generative models for drug discovery and repurposing and large-scale dynamic GNNs. I am also interested in leveraging AI for climate modelling.
Close
My interest in academic subjects includes physics and soft computing.
I hold a BE in Electronics and Communication from the PSG College of Technology, Coimbatore. I received the KIAC predoctoral fellowship KIAC in August 2024 and my faculty mentor is Professor Pandarasamy Arjunan, Energy Informatics Lab, Robert Bosch Centre for Cyber-Physical Systems, IISc.
I analyse the applicability of time series foundation model for energy load forecasting for various commercial and residential buildings. In future, I would like to design, develop, and integrate a comprehensive AI ecosystem into an unified system that ensures ethical human-AI collaboration, prioritises safety and fairness, and provides scalable solutions to address global challenges.
Close
I am truly passionate about improving reasoning in large language models (LLMs) and making them more intelligent, while also enabling faster inference. Apart from this, I am also interested in multilingual LLMs, automated speech recognition (ASR), and also computer vision problems.
I am a graduate in Computer Science and Engineering from the Kalinga Institute of Industrial Technology, Bhubaneswar, Odisha. I am currently working as a predoctoral fellow under the guidance of Professor Radhakant Padhi in the Aerospace Systems Lab, Department of Aerospace Engineering, IISc.
My work here mainly focusses on leveraging automated speech recognition systems to enhance and build robust air traffic control (ATC) pilot communication systems and ATC training tools. By developing more accurate and adaptive ASR solutions, our aim is to make aviation communication more reliable, efficient, and safe. Looking ahead, I plan to pursue a PhD in ML and work on problems combining natural language processing and computer vision and work on multimodal systems which are actually very robust and intelligent.
Close
I am interested in learning-based control and deep learning.
I have completed my MTech (Systems and Control - Electrical) from the Indian Institute of Technology Roorkee, Roorkee and BTech (Electrical and Electronics) from the Visvesvaraya National Institute of Technology, Nagpur. I received the predoctoral fellowship from KIAC in August 2024 and I am currently working with Professor Pushpak Jagtap in the FOCAS Lab, Robert Bosch Centre for Cyber-Physical Systems, IISc.
My research is on learning-based control for unknown systems. My long-term goal is to advance the field of learning-based control and safety by developing innovative, data-driven control algorithms that function reliably in real-world, dynamic environments. I believe that learning-based systems have the potential to revolutionise industries, by enhancing safety, efficiency, and sustainability. Specifically, my research focusses on creating robust control systems that can adapt in real-time to unexpected scenarios, thereby enhancing safety. I am particularly interested in integrating machine learning models with control theory to develop adaptive, predictive control strategies capable of responding dynamically to complex, unstructured environments.
Close
My research interests are in computational fluid dynamics, machine learning, fluid mechanics, and high performance computing.
I hold a BE in Mechanical Engineering (2019-2023) from the Birla Institute of Technology and Science Pilani, Goa campus. My predoctoral fellowship from KIAC commenced in May 2024 under the guidance of Professor Aravind Balan in the Computational Aeroscience Lab, Department of Aerospace Engineering, IISc.
My current research involves the implementation of sequential ensemble models to predict computationally-expensive adjoint-based error estimator for expediting the metric-based mesh adaptation process. My future goal is a PhD in the field of computational fluid dynamics.
Close
I am especially passionate about understanding and improving neural network training processes through topological analysis techniques, such as persistent homology and Reeb graphs, to enhance model performance and interoperability.
I completed my BTech in Information Technology from the A. K. Choudhury School of Information Technology at the University of Calcutta, Kolkata. From July 2024, I am a KIAC predoctoral fellow in the Visualization and Graphics Lab at the Department of Computer Science and Automation, IISc, under the guidance of Professor Vijay Natarajan. I aspire to pursue a PhD in the future.
Close
I am particularly interested in applying artificial intelligence and machine learning to address complex challenges across engineering and scientific disciplines.
I completed my BTech in Mechanical Engineering at the Vellore Institute of Technology, Vellore, from 2020 to 2024. Under the guidance of Professor Ananth Govind Rajan in the AGR Lab, Department of Chemical Engineering at IISc, I began the KIAC predoctoral fellowship in August 2024.
My research focusses on generative AI for the synthesis of two-dimensional materials, where I am exploring AI-driven approaches in material science.
Close
My research interests include deep learning and its application in robotics.
I am a graduate in Electrical and Electronics Engineering from the Thiagarajar College of Engineering, Madurai. Currently, I am a KIAC predoctoral fellow working under the guidance of Professor Ravi Prakash in the Human-Interactive Robotics (HiRo) Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc.
Presently, I am working to impart throwing skills to robotic manipulators using self-supervised learning, where a robotic manipulator is trained to throw objects with varying properties, including differences in mass, mass distribution, and density into a defined target position. This work is a step toward developing adaptive, skilful robotic systems capable of handling complex and dynamic tasks. My goal is to lead a research laboratory focussed on robot skill learning, and I am certain that the experiences I am gaining as a KIAC predoctoral fellow are helping me achieve this!
Close
In my free time, I enjoy exploring the local culture and monuments through the lens of my drone.
I completed my BTech in Electronics and Communication Engineering from the Vellore Institute of Technology (VIT), Vellore in 2023. During my Bachelor's, I worked on deep learning-based decision-making models for autonomous vehicles in VIT’s Automotive Research Centre. I completed my Bachelor's thesis at the Biomedical and Health Technology Group at ETH Zürich. Since October 2023, I am working as a predoctoral fellow supported by the Kotak IISc AI–ML Centre, with Professor Vaibhav Katewa at the Robert Bosch Centre for Cyber-Physical Systems (CPS).
I am currently working on fault detection and tolerance in autonomous and intelligent systems at CPS. I have been accepted and plan to join Carnegie Mellon University to pursue a Master’s in Electrical and Computer Engineering from January 2025.
Close
I completed my BTech in Electronics and Communication from the University of Kashmir, Jammu and Kashmir, in 2023. During my undergraduate studies, I developed a strong foundation in electronics, AI/ML, computer systems, and architecture. This interest led me to further explore the optimisation of hardware and software, particularly in system designs. In August 2023, I joined IISc as a Project Associate, where I worked on optimising 2.5D systems, also known as chiplet-based systems. I am working under Professor Sumit Kumar Mandal in the Future Computing Systems Lab, focussing on improving the cost-effectiveness of chiplet architectures, particularly for server applications.
In November 2023, I received the Kotak IISc AI-ML Centre's predoctoral fellowship, where I continue to develop an innovative tool for optimising 2.5D system configurations. The tool I am working on aims to strategically place processing elements within chiplets, ensuring that the system meets user-defined constraints while maximising performance. The goal is to create a solution that delivers performance within a smaller percentage of the optimal, as estimated by a cycle-accurate simulator. Looking ahead, I am planning to pursue research in computer systems, with a focus on computer architecture.
Close
I have been interested in understanding how we make decisions and in turn, the neural basis of behaviour. Also importantly, can we nudge it to reach a strictly better state?
I completed an Interdisciplinary Dual Degree from the Indian Institute of Technology Bombay, Mumbai. I did my Bachelor's in Civil Engineering, and my Master's in Artificial Intelligence and Data Science. I am currently a KIAC predoctoral fellow and I am very fortunate to work with Professor Sridharan Devarajan from the Centre for Neuroscience, IISc, where I am leveraging my computational skills and advances in generative models to reach my goal.
Through my research, I aim to contribute to a deeper understanding of the neural mechanisms underlying decision-making and to develop novel strategies for behaviour modification.
Close
I am interested in computer vision and AI for social impact and policy making.
I completed my BTech in Computer Science and Engineering (CSE) from the Jawaharlal Nehru Technological University Kakinada, Andhra Pradesh and MTech (CSE) from the Jawaharlal Nehru University, New Delhi. I received the predoctoral fellowship from KIAC in July 2024, and I am working with Professor Rajiv Soundararajan in the Visual Information Processing lab at the Department of Electrical Communication Engineering, IISc.
I am currently working on building efficient multi-modal LLM (large language model) architectures for AI-generated image quality assessment. I want to use the knowledge I gain through my research to build products and processes that will assist policy-making and social impact in the future.
Close
My research interests lie in robot learning, particularly in planning that integrates multiple modalities. I am also intrigued by the cognitive capabilities of intelligent systems, such as machine learning with combinatorial constraints for structure synthesis.
I completed my Bachelor's in Electrical Engineering from the Indian Institute of Technology Mandi, Himachal Pradesh, in 2024. My final year project focussed on meta-learning for long-horizon manipulation, where I synthesised subskills by observing human actions. During my undergraduate studies, I participated in semester exchange programmes at TU Darmstadt and NTNU Norway, where I concentrated on courses and skills related to robotics and AI. In June 2024, I joined as a KIAC predoctoral fellow under Professor Ravi Prakash in the Human Interactive Robotics Lab, Robert Bosch Centre for Cyber-Physical Systems, IISc.
Together, we have been working on improving human-robot interaction by using language as an interface. Our approach involves translating open-vocabulary language commands into mathematical modifications of waypoints, with code serving as the intermediary. Currently, my work focusses on planning for bi-manual object arrangement tasks and extracting explainable affordances for these problems. I aspire to deepen my understanding of the interplay between brains, minds, and machines, and the work in my lab has been instrumental in guiding me towards this goal.
Close
I have completed my MTech in Computer Science and Automation under the guidance of Professor Shalabh Bhatnagar from IISc. In 2024, I joined the PhD programme at IISc under the mentorship of Professor Punit Rathore in the VISTA Lab at the Robert Bosch Centre for Cyber-Physical Systems.
I was awarded the KIAC PhD scholarship in August 2024.
Research focus: My current research is centred around human-computer interaction, computational sensorimotor learning, representation learning, and unsupervised learning. I am particularly interested in how machines can learn to process and understand sensory input in ways that mirror human perception and cognition. Through this work, I aim to contribute to the development of intelligent systems capable of performing tasks autonomously, reducing the need for human intervention and improving human-computer collaboration.
Looking ahead, I aim to continue advancing research at the intersection of machine learning and cognitive science. I envision creating more adaptive, flexible AI systems that can autonomously learn from sensory data and seamlessly interact with the environment. By refining techniques in sensorimotor learning and representation learning, I hope to contribute to AI technologies that will integrate more intuitively into daily life, facilitating smoother interactions between humans and machines in real-world settings.
Close
My research interests lie in improving the generalisation and robustness of machine learning models under distribution shifts.
I earned my BTech in Electrical Engineering from the Indian Institute of Technology Kharagpur, Kharagpur. In May 2024, I was awarded the KIAC predoctoral fellowship and I have since been conducting research under the guidance of Professor Prathosh A P in the Representation Learning Lab at the Department of Electrical Communication Engineering, IISc.
My previous work includes contributions to unsupervised domain adaptation and domain generalisation in medical imaging, leveraging energy-based models for image-to-image translation and data augmentation to enhance medical image segmentation. Currently, my research focusses on improving zero-shot adversarial robustness in vision-language models. My future goal is to pursue a PhD focussed on advancing representation learning for vision-based models through unsupervised and self-supervised learning, with the aim of developing efficient and generalisable frameworks for visual data understanding.
Close
My academic interests lie in signal processing and computer vision.
I have completed my MTech in Communications and Signal Processing with a specialisation in Machine Learning at the Indian Institute of Technology Mandi, Himachal Pradesh after earning my BTech in Electronics and Communication Engineering from Guru Gobind Singh Indraprastha University, Delhi. Currently, I am undertaking a predoctoral fellowship from KIAC, which I began in September 2024, under the guidance of Professor Anirban Chakraborty in the Visual Computing Lab at the Department of Computational and Data Sciences, IISc.
I am pursuing research in enhancing federated learning using pre-trained vision-language models and source-free domain adaptation.
Close
My academic interests lie in linear algebra, computer vision, and deep learning.
I graduated from the Birla Institute of Technology and Science Pilani, K K Birla Goa campus, in 2024 with a BE in Computer Science. After graduating from college, I wanted to gain more research experience to better understand the life of a researcher and learn more about the latest innovations in computer vision. I received the KIAC predoctoral fellowship in June 2024 and joined Professor Rajiv Soundararajan's lab right after graduation. I work in visual quality assessment under his guidance in the Visual Information Processing Lab at the Department of Electrical and Communication Engineering, IISc.
My work delves into the development of human preference-aware image quality assessment methods for AI-generated images. Moving forward, I plan on continuing research in computer vision and using the experience gained at the lab to contribute impactful ideas to the field.
Close
I am interested in multimodal alignment and the generalisability of models to unseen or adverse conditions, such as those encountered by autonomous driving agents. Additionally, I am keen to work in explainable AI, where we study how a model arrives at its decisions, aiding the end user in assessing its fairness.
I hold a Bachelor's degree in Electronics and Telecommunications Engineering from Pune University. Currently, I am undertaking my predoctoral fellowship under the guidance of Professor Suresh Sundaram in the Artificial Intelligence and Robotics Laboratory (AIRL), Department of Aerospace Engineering, IISc. I commenced my fellowship in August 2024, working alongside Mr Aniruddh Sikdar (PhD student).
Our research focusses on domain generalisation and open-vocabulary learning, with end applications in autonomous systems.
Close
My research interests lie in leveraging machine learning to advance Earth system science and deepen our understanding of ecosystem responses to environmental changes.
I hold a BTech in Mechanical Engineering from the National Institute of Technology Kurukshetra, Haryana and an MTech in Climate Science from the Indian Institute of Science, Bengaluru. In July 2024, I received the KIAC predoctoral fellowship and have the privilege of working with Professor Deepak Subramani in the QUEST Lab at the Department of Computational and Data Sciences, IISc.
My current work focusses on applying neural operators to oceanography.
Close
I got my BTech from the Indian Institute of Technology Madras, Chennai. After that, I started working as a project associate in the VAL lab at the Department of Computational and Data Sciences under Professor Venkatesh Babu Radhakrishnan. I received the KIAC predoctoral fellowship in August 2024.
I am working on generative models and image editing. In future, I want to pursue higher studies on the current topic I work on.
 I joined the BTech programme in Mathematics and Computing at the Indian Institute of Science in 2022. My faculty advisor, Professor Viraj Kumar, has guided my academic journey, and I had the opportunity to work under his mentorship during the summer of 2024.
I joined the BTech programme in Mathematics and Computing at the Indian Institute of Science in 2022. My faculty advisor, Professor Viraj Kumar, has guided my academic journey, and I had the opportunity to work under his mentorship during the summer of 2024. I joined BTech at IISc in 2024.
I joined BTech at IISc in 2024.





 I joined the BTech programme in 2024. My faculty advisor is Professor Viraj Kumar. I am interested in computer science and would like to do research in computer science in the future.
I joined the BTech programme in 2024. My faculty advisor is Professor Viraj Kumar. I am interested in computer science and would like to do research in computer science in the future. Anmol Gill pursues the MTech (Artificial Intelligence) programme at IISc, in the Robert Bosch Centre for Cyber-Physical Systems (
Anmol Gill pursues the MTech (Artificial Intelligence) programme at IISc, in the Robert Bosch Centre for Cyber-Physical Systems (
















 I recently completed my BTech in August 2024 from the Vellore Institute of Technology, Chennai, with a major in Electronics and Communication Engineering. From May 2024, I am a research intern, supported by the Kotak-IISc AI/ML Centre, in the Human-Interactive Robotics (HiRo) Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc. I am working under the guidance of Professor Ravi Prakash. My essential area of interest lies in robot learning, which lies under the general area of AI and robotics.
I recently completed my BTech in August 2024 from the Vellore Institute of Technology, Chennai, with a major in Electronics and Communication Engineering. From May 2024, I am a research intern, supported by the Kotak-IISc AI/ML Centre, in the Human-Interactive Robotics (HiRo) Lab at the Robert Bosch Centre for Cyber-Physical Systems, IISc. I am working under the guidance of Professor Ravi Prakash. My essential area of interest lies in robot learning, which lies under the general area of AI and robotics.






















